

限时折扣 · 特惠云






DeepSeek + Ollama + Cherry Studio搭建本地私有知识库
发布时间:2025-03-02 17:27
阅读量:2567
一、什么是知识库?
知识库(Knowledge Base)是一个存储和管理知识的系统,通常包含结构化和非结构化的信息,用于帮助用户或系统快速查找和获取相关知识。
你可以把它想象成一个“知识仓库”,里面存放着各种有用的信息,比如文档、常见问题解答(FAQ)、数据库、规则、案例等。
举个栗子:
假设你是一名技术客服人员,客户问你一个关于某个产品的问题。 如果你有一个完善的知识库,你可以直接在知识库中搜索相关产品的使用说明或常见问题解答,快速找到答案并回复客户。 如果没有知识库,你可能需要去问同事或查找一堆文档,效率会低很多。
二、为什么要搭建个人知识库?
搭建个人知识库不仅能提升工作效率,还能促进持续学习和团队协作,对个人职业发展和团队知识管理具有长远意义。
1. 知识系统化
- 集中管理:将零散的知识点整合到一个平台,便于查找和使用。
- 结构化存储:通过分类和标签,使知识更易管理和检索。
2. 提升效率
- 快速检索:通过搜索功能迅速找到所需信息,减少重复查找时间。
- 减少重复劳动:避免重复解决相同问题,提升工作效率。
3. 持续学习
- 积累经验:记录问题和解决方案,形成个人经验库。
- 知识更新:持续更新知识库,保持技术前沿。
4. 团队协作
- 知识共享:团队成员可访问知识库,促进经验交流。
- 减少沟通成本:常见问题和解决方案在知识库中共享,减少重复沟通。
如果想要搭建知识库,这里我们又不得不提到另外一个词——RAG.
三、什么是RAG?
RAG(Retrieval Augmented Generation,检索增强生成)是一种让大语言模型(LLM)变得更聪明的方法。
简单来说,它通过给模型提供一个外部的“知识库”,让模型在回答问题时可以“查资料”,从而给出更准确、更相关的答案。
举个栗子:
想象一下,大模型就像一个学生,而RAG系统就是一本字典。 当学生遇到不懂的问题时,他可以翻开字典查找相关的解释,然后再根据字典里的内容回答问题。 这样,学生不仅能回答得更准确,还能避免“瞎编”答案。 那么,当大模型遇到不懂的问题时,他也可以查字典,也就是RAG系统。
四、有了大模型,为什么还需要RAG?
- 大模型的知识有限:大模型的知识主要来自它训练时用的数据,而这些数据是有限的,尤其是企业内部的业务知识或产品信息,模型可能完全不了解。
- 微调成本高:如果想让大模型学习企业特定的知识,通常需要微调模型,但这不仅成本高,而且效果也不一定好。
- 幻觉问题:大模型在不熟悉的领域可能会“瞎编”答案,这在企业应用中是不可接受的,尤其是那些需要准确信息的场景。
这里,我先贴出一个 RAG 的运作流程图。
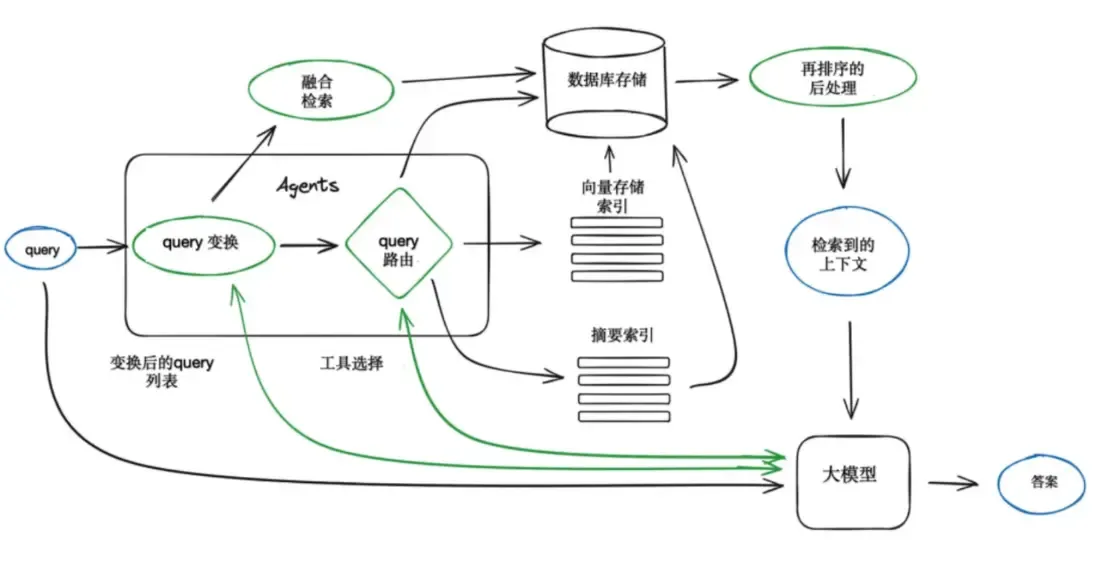
RAG运作图
好了,废话不多说,接下来就带大家具体实操了,
如何用DeepSeek + Ollama + Cherry Studio在本地搭建私有知识库。
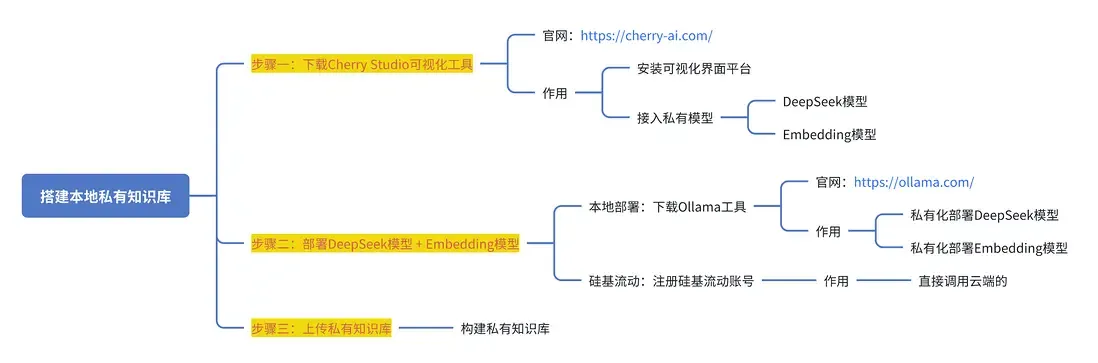
私有知识库搭建
五、搭建实操
1. 软硬件配置说明
(1)硬件: 公司标配的办公电脑 Apple M3 Pro 36GB
(2)软件:cherry studio v0.9.21 下载, ollama 下载
(3)基础模型为:deepseek-r1:7b (ollama 内置下载)
(4)嵌入模型为:bge-m3 (ollama 内置下载)
2. 步骤说明
步骤一:下载安装Cherry Studio可视化工具
官网直接下载安装,毋庸赘述。 cherry studio v0.9.21 下载
步骤二:部署DeepSeek模型 + Embedding模型
那么,这里又分为两种方式
方式一:使用Ollama工具本地运行 DeepSeek R1
好处: 可以实现本地部署DeepSeek模型 + Embedding模型,免费、安全
坏处: 受到本地电脑配置的限制,只能使用蒸馏版,推理能力远不如满血版,本文以 DeepSeek R1 7B 版本为例。
方式二:调用第三方平台服务 API
好处: 不用本地部署,可以使用完整的模型服务
坏处: 调用云端的模型服务需要一定的费用,但是也不贵。比如硅基流动,不过实测最近硅基api很卡,有时比 ds 官网还卡。
因为我自己搭建的知识库会用到很多内部资料,出于安全性考虑今天我们重点介绍的是第一种方式———使用Ollama工具本地运行 DeepSeek R1 ,借助Cherry Studio嵌入本地资料,搭建本地私有知识库。
本地安装 ollama 并下载需要的模型。 官网下载ollama 下载 并安装后,打开任意终端, 如图输入以下两个命令来下载并运行 deepseek-r1 和 beg-m3,基础模型为deepseek-r1:7b, 嵌入模型为bge-m3, 需要联网下载,时间会比较久, 耐心等待提示成功即可。
ollama run deepseek-r1:7b

运行 deepseek-r1 成功后,可以再终端进行问答测试

ollama pull bge-m3

步骤三:在 Cherry Studio 中配置模型
如图,在 Cherry Studio 设置页面配置模型服务,选择 Ollama, 模型选择弹窗中选中 deepseek-r1:7b 和 bge-m3:latest
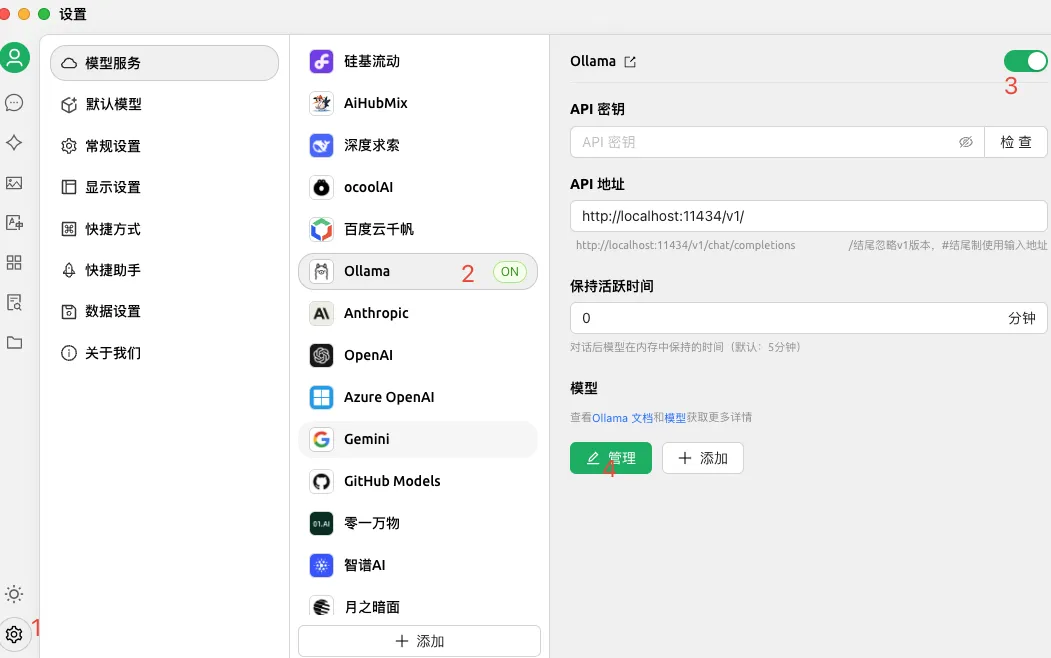
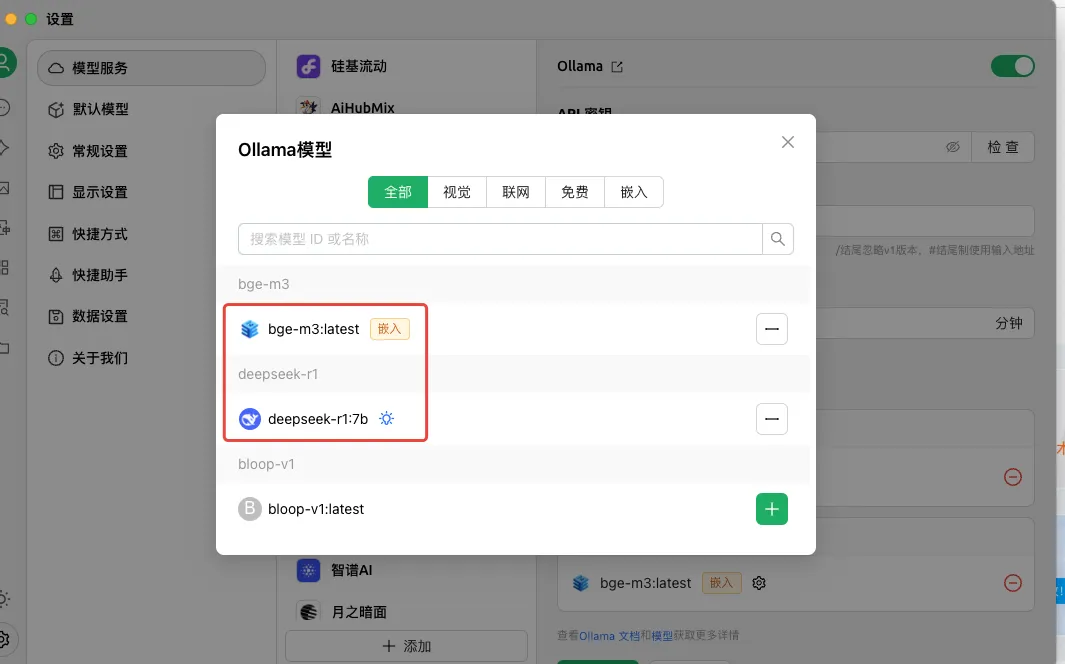
配置模型成功后应该如下图所示,也可以点击 check 按钮进行验证。
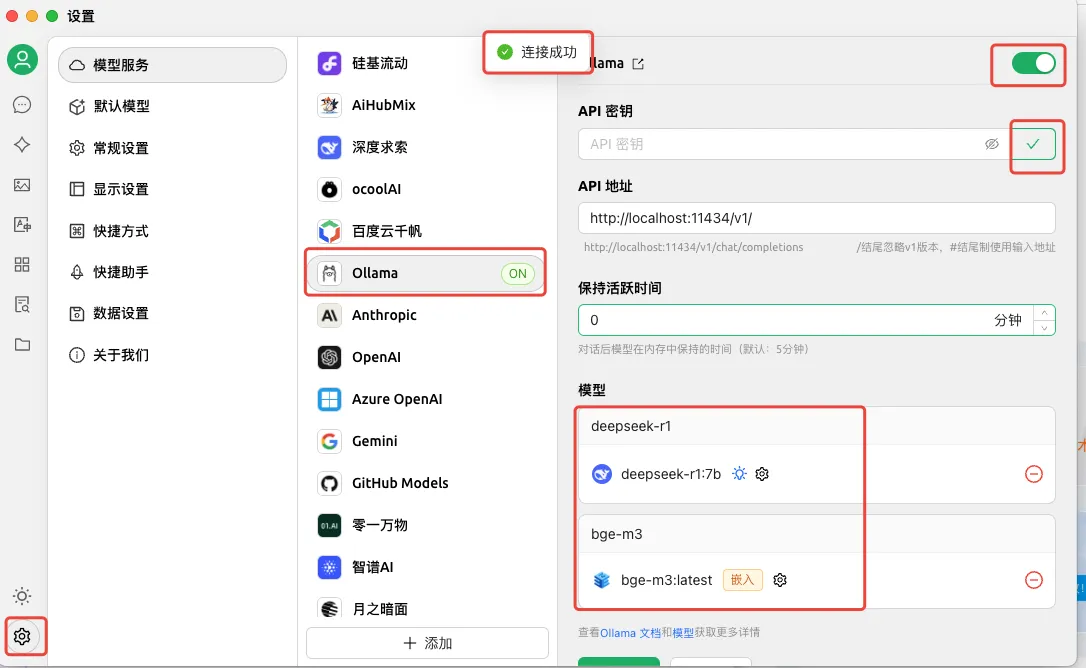
步骤四:在 Cherry Studio 中构建知识库
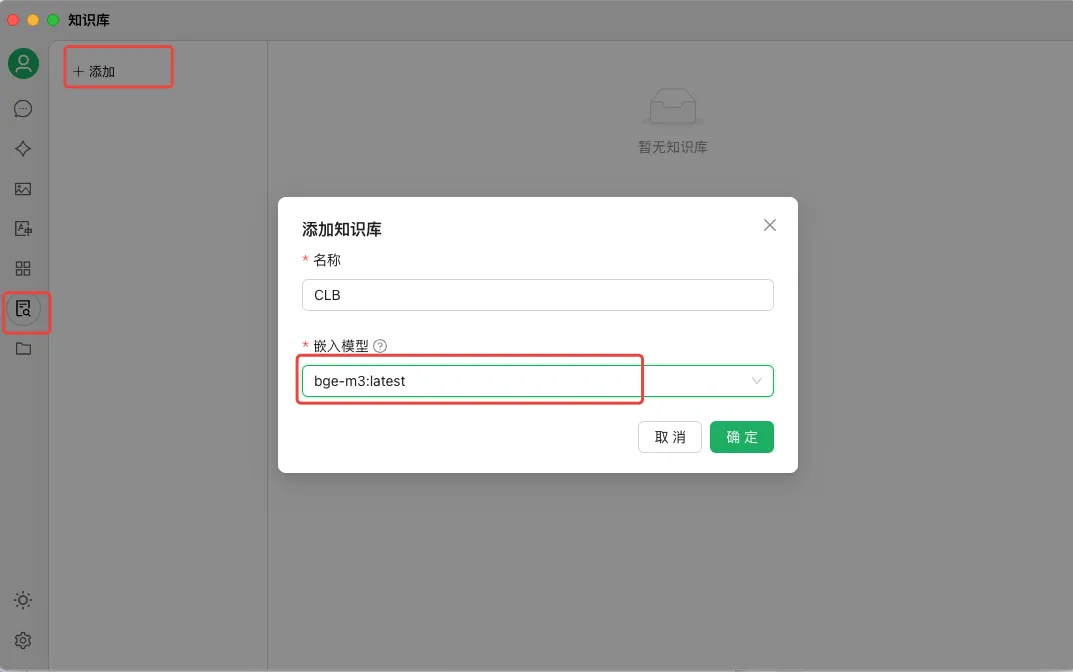
在Cherry Studio 知识库配置页卡中,按照自己的需要新建【知识库】,嵌入模型选择【bge-m3:latest】, 然后上传知识库素材,可以添加文档(支持pdf/doc/xlsx/ppt/txt/md 等),也可以添加目录(这个极其方便)、网站等,添加完以后出现绿色的对号,表示向量化完成。
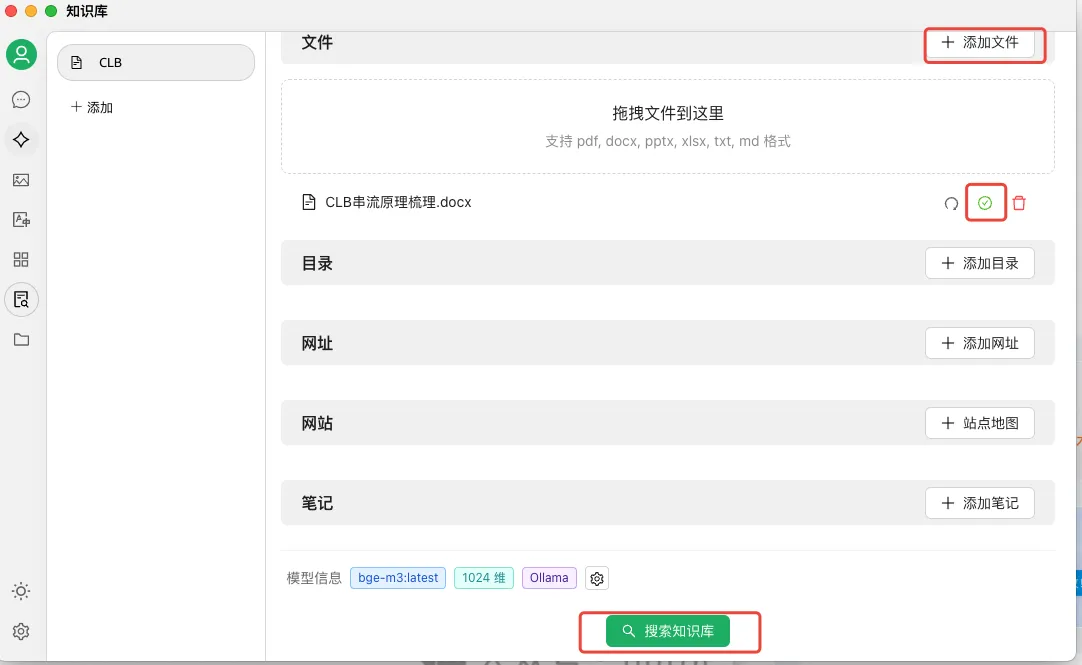
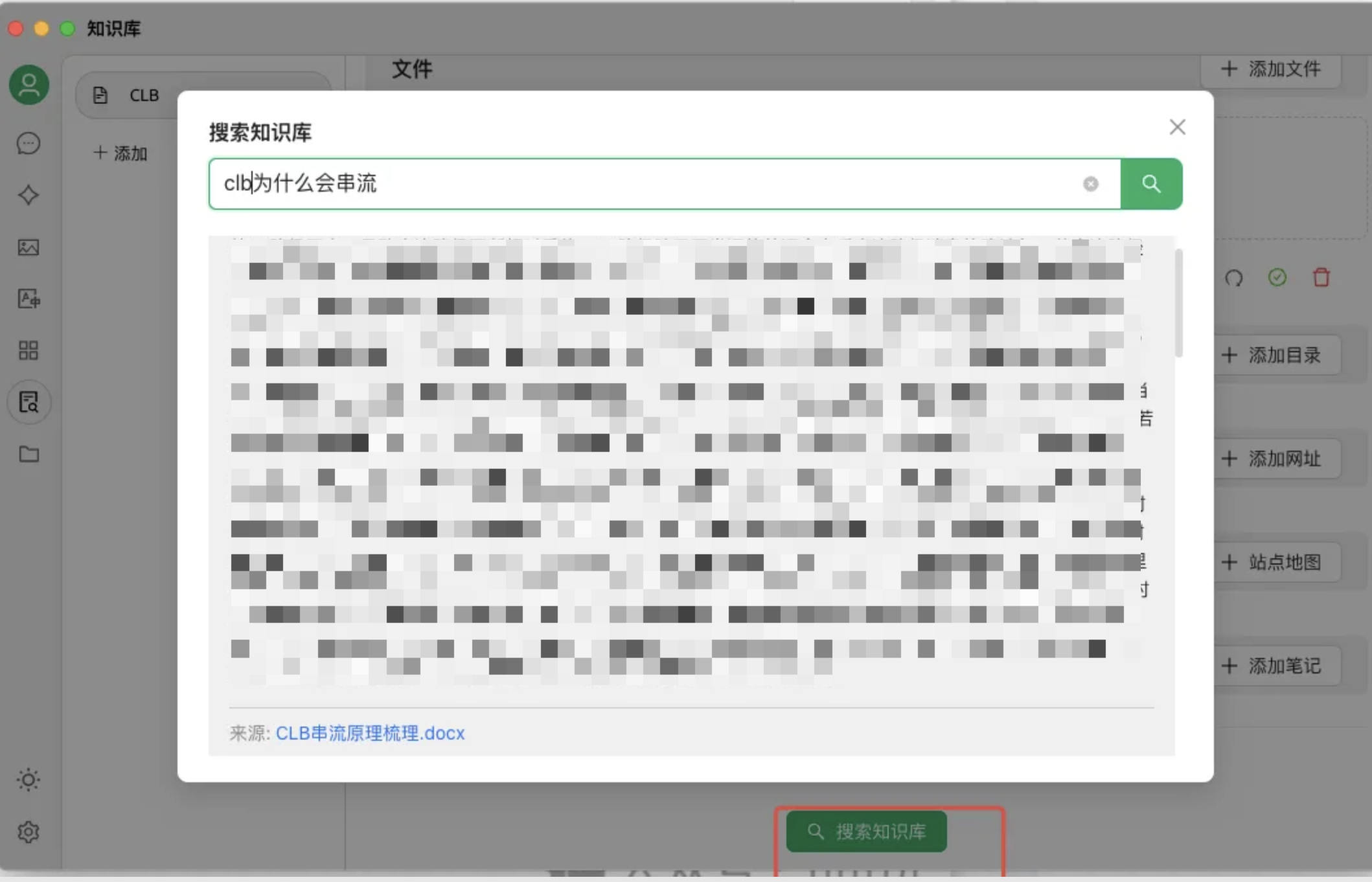
添加素材完成后,可以使用【搜索知识库】进行测试验证,如下图所示,我这里提供的素材是 clb 串流原理的文档,所以提问了【clb为什么会串流?】。模型会根据知识库中的素材进行回答,并标注来源和匹配度等。
步骤五:在 Cherry Studio 中构建智能助手
经过上面的步骤,我们的大模型和个人知识库其实已经搭建好了, 后续有新的素材可以重复步骤四补充进去,让知识库越来越丰富。接下来就是通过Cherry Studio 提供的聊天助手来更加方便的使用我们的知识库了。
如图可以使用默认的聊天助手,也可以新建一个自定义的聊天助手,选择本地模型和知识库, 这样默认这个聊天助手所有的问答都会参考我们的知识库资料。同理也可以搭建多个知识库和多个聊天助手,满足不同的使用场景。 其实 Cherry Studio 中已经默认配置了很多助手,比如产品助手、运维助手、软件开发助手等等,大家可以按需使用。
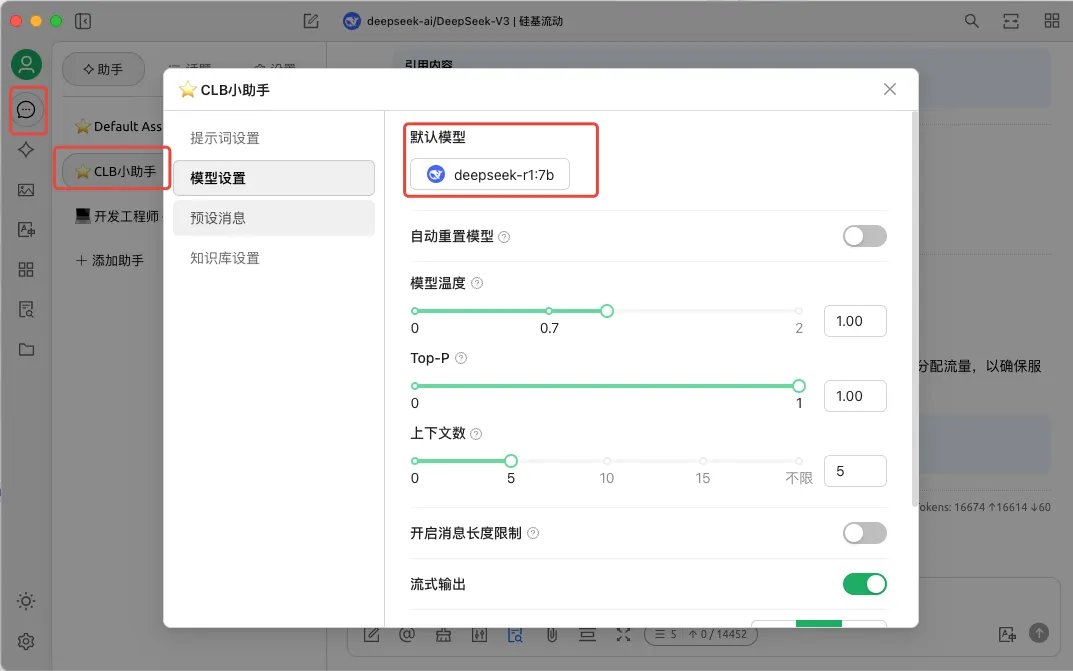
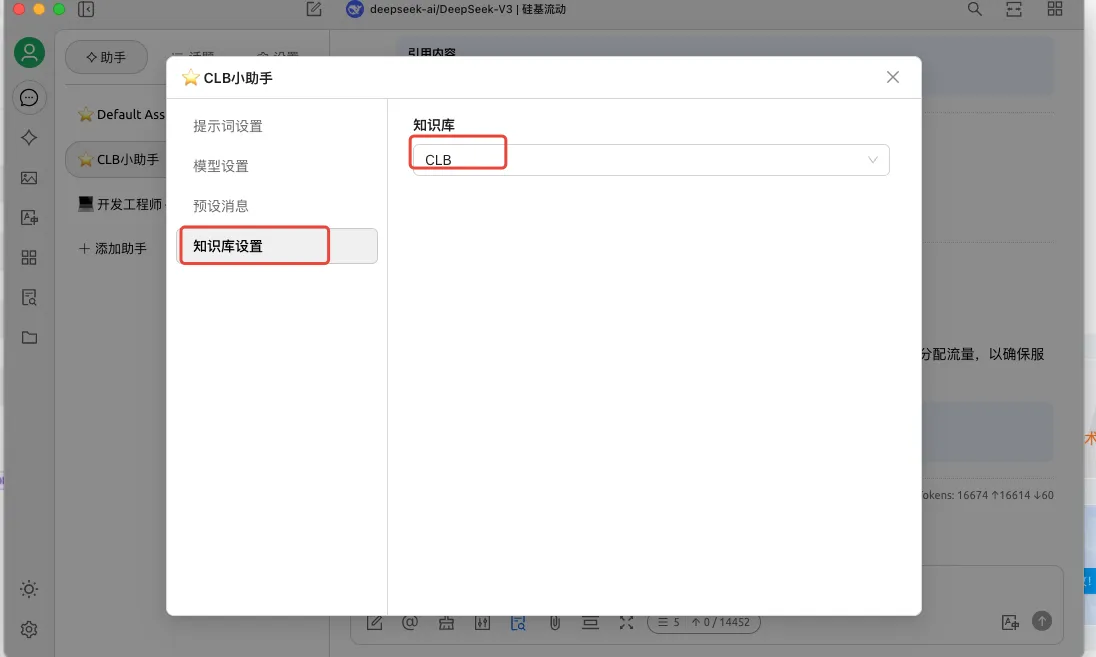
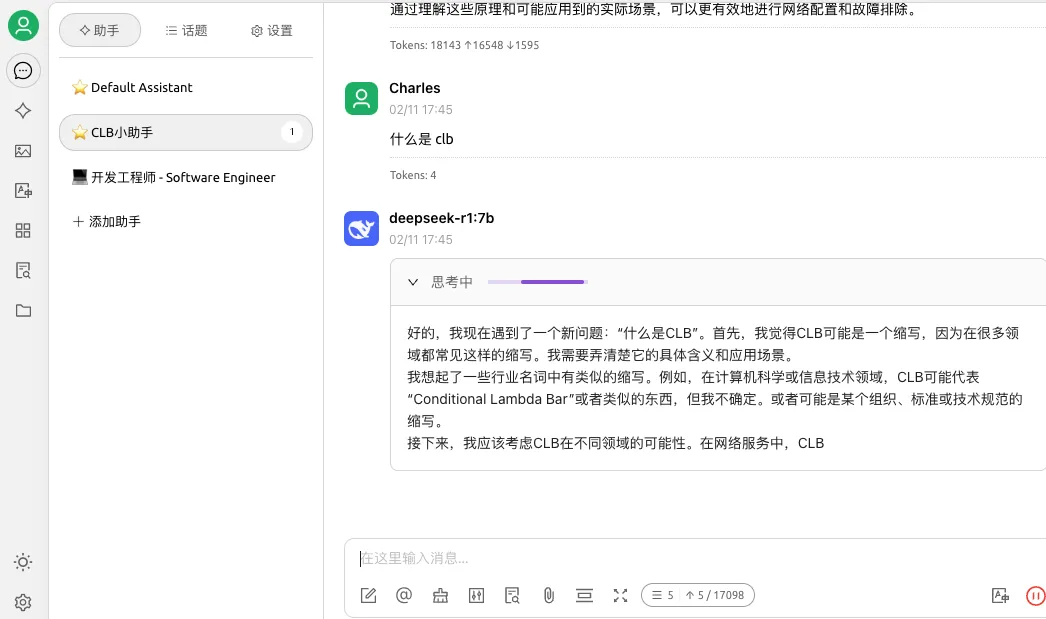
当然也可以在聊天页面,选择使用哪个知识库进行推理,或者不使用知识库,让大模型基于通用知识进行推理。
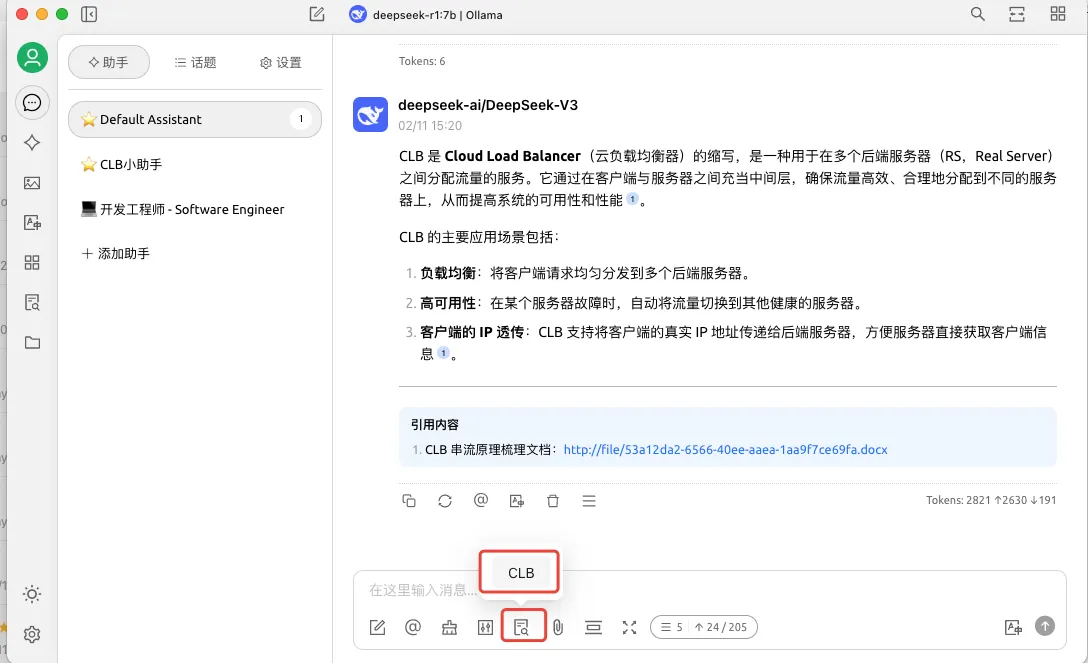
好了,到这里相信你已经拥有了属于自己的知识库和智能助手, 预祝你可以在 AI时代,更加智能和高效的工作。
另外,受限于工作机配置原因,我们这里使用的是 ds-r1:7b 版本,如果想要使用满血版的 deepseek 可以参照步骤二中的方式一使用付费服务或者自己购买千寻云 HAI进行部署。如果需要使用其他大模型,部署步骤和 deepseek 类似,可以根据自己的电脑配置,酌情选择。
六、未来已来:重新定义程序员的战场
历史上,C语言没有淘汰汇编工程师,而是让他们转向嵌入式开发;云计算没有让运维消失,而是催生了DevOps专家。
AI时代程序员的生存法则:
- 将DeepSeek视为“外接大脑”,专注需求抽象(从业务到数学模型)
- 修炼系统思维(复杂问题拆解能力)
- 保持技术敏锐度(通过联网搜索持续进化)
正如DeepSeek-R1在解答数学难题时需要172秒的深度思考,程序员真正的价值,在于在混沌中定义问题边界的能力——而这正是AI至今未能突破的"人类智慧结界"。
记住:淘汰你的从来不是AI,而是会用AI的其他程序员。














